
مکانیابی بهینه - تحلیل چندمعیاره در محیط GIS
سیستم اطلاعات جغرافیایی, سامانه اطلاعات جغرافیایی,سامانه اطلاعات مکانی, نرم افزار, ژئوپرتال, تحلیل چندمعیاره, GIS, WebGIS, Web-GIS,Software, GIS-Software, Geoportal, Mobile-GIS, geoprocessing, Multi Criteria Overlay, Weighted Raster Overlay, Toturial
رشد روزافزون شهرنشینی و افزایش ترافیک، نیاز به توسعه سیستمهای حملونقل پایدار و دوستدار محیط زیست را بیش از پیش ضروری ساخته است. دوچرخهسواری به عنوان یکی از مؤثرترین روشهای حملونقل پاک، علاوه بر کاهش آلودگی هوا و ترافیک، فواید بسیاری برای سلامت شهروندان دارد. با این حال، گسترش فرهنگ استفاده از دوچرخه نیازمند تأمین زیرساختهای حمایتی مناسب، از جمله فراهم کردن پارکینگهای کافی، ایمن و در دسترس است.
یکی از چالشهای اساسی در توسعه شهری، تعیین مکانهای بهینه برای احداث فضاهای جدید خدماتی مانند پارکینگ دوچرخه است. این فرآیند مستلزم تحلیل دقیق عوامل مختلف مؤثر بر نیاز و کارایی این فضاها میباشد. سیستمهای اطلاعات جغرافیایی (GIS) با قابلیتهای قدرتمند در مدیریت، تحلیل و نمایش دادههای مکانی، ابزار بسیار مناسبی برای کمک به اینگونه مطالعات مکانیابی محسوب میشوند.
تحلیل چندمعیاره (Multi Criteria Analysis - MCA) که با روشهای مختلفی از جمله همپوشانی لایههای اطلاعاتی (Overlay) در محیط GIS قابل پیادهسازی است، امکان ارزیابی همزمان چندین معیار را فراهم میکند. در این روش، لایههای اطلاعاتی مختلف با توجه به اهمیت نسبی هر کدام، ترکیب شده و منطقه یا مناطقی را که بهترین شرایط را بر اساس مجموع معیارها داراست، شناسایی و معرفی میکند.
در این یادداشت به عنوان نمونه، مکانیابی بهینه پارکینگهای جدید دوچرخه، با رویکردی ترکیبی از تحلیل رستری و مکانیابی چندمعیاره را در یک محدوده شهری خاص بررسی می کنیم.
دادههای برداری موجود شامل موقعیت سرقتهای دوچرخه، مسیرهای دوچرخهسواری و پارکینگهای فعلی، به لایههای رستری با وزندهی مناسب تبدیل شده و سپس با استفاده از الگوریتم همپوشانی رستری، مناطق با اولویت بالا برای احداث پارکینگهای جدید شناسایی خواهند شد.
مفاهیم، ابزارها و روالی را که ما استفاده خواهیم کرد در اغلب نرم افزارهای پردازش مکانی با کمی اختلاف وجود دارند، با این وجود رویکرد ما در این تجربه استفاده از امکانات موجود در سامانه Geopack Geoportal خواهد بود تا با امکانات برخط این سامانه بیشتر آشنا شوید.
در ویدئوی زیر می تواند نحوه ی اجرای گردشکار نمونه برای این پردازش را در این سامانه مشاهده کنید:
آماده سازی داده های مکانی
داده های ورودی مورد استفاده برای شروع کار به شرح زیر هستند:
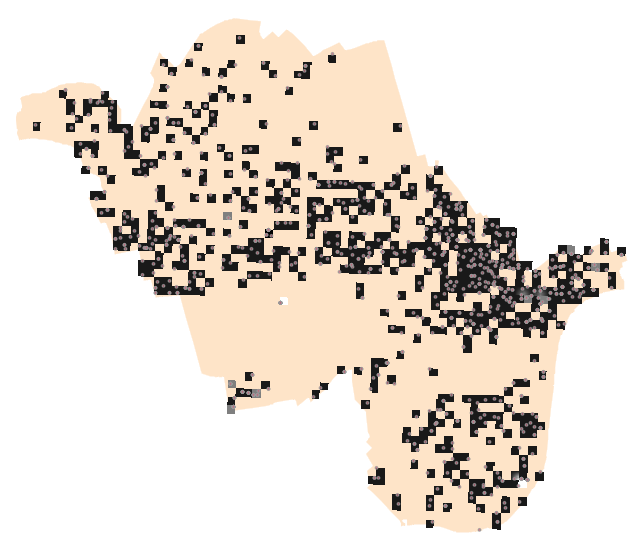
- نقاط سرقت دوچرخه: شامل یک لایه نقطه ای که موقعیت رویداد سرقت دوچرخه را نشان می دهد. در این لایه رویدادهای تکراری در یک محل به صورت عوارض نقطه ای تکراری وجود دارند.
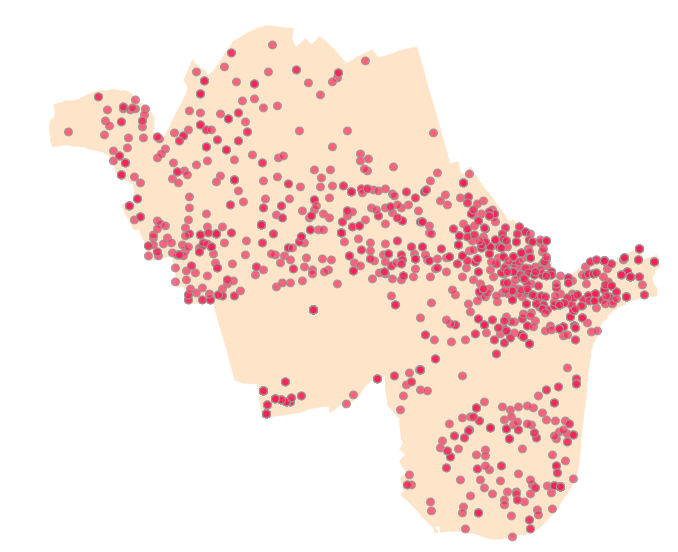
لایه دزدی دوچرخه-نقاط پررنگتر تکرار سرقت را نمایش می دهند
- پارکینگ های موجود: لایه نقطه ای نشان دهنده موقعیت پارکینگ های موجود در سطح منطقه مطالعه.
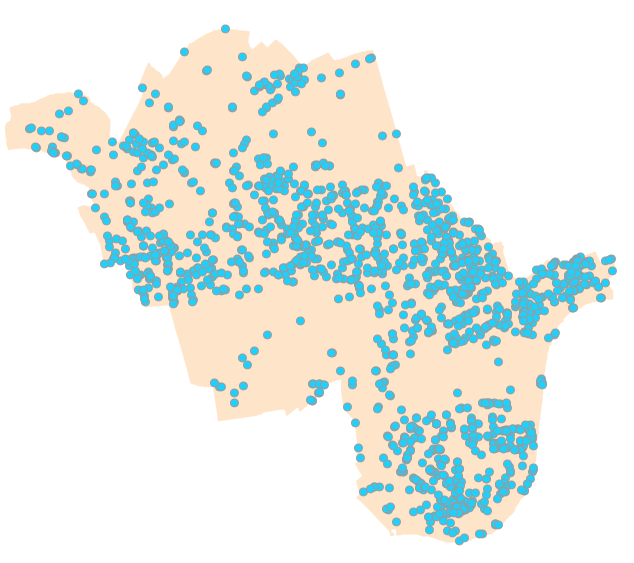
لایه پارکینگ های موجود
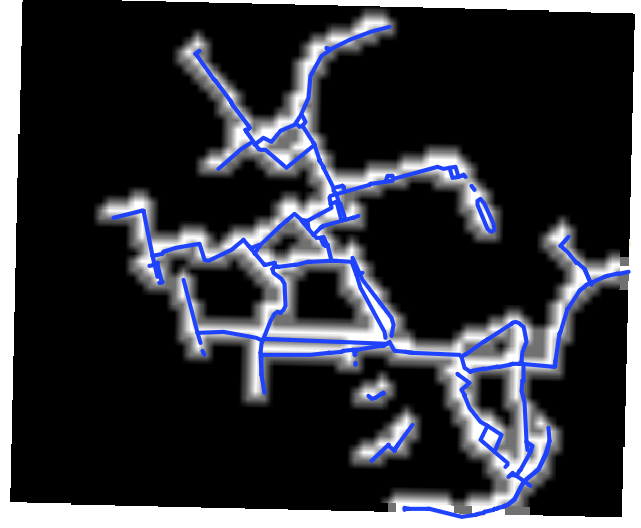
- مسیر دوچرخه سواری: لایه خطی نشان دهنده مسیرهای دوچرخه سواری در منطقه
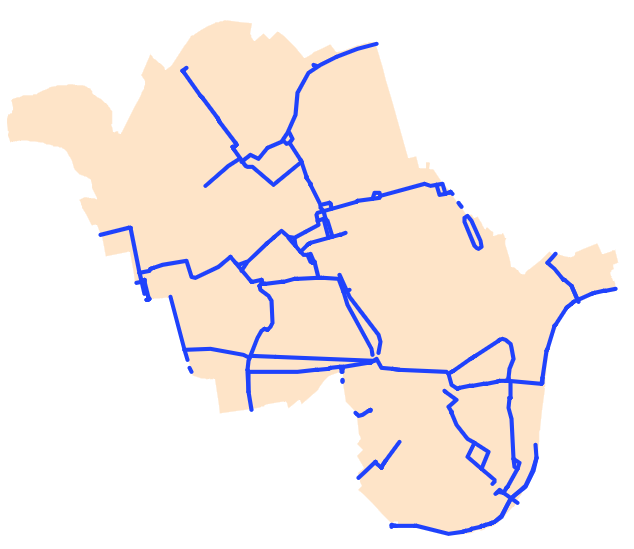
لایه خطی مسیر دوچرخه سواری
- محدوده و سیستم مختصات داده ها:
بهتر است که لایه های داده مکانی در یک سیستم مختصات یکسان آماده سازی شده باشند و از آنجایی که در تحلیل نزدیکی (Proximity) از فاصله اقلیدسی تا عوارض استفاده می شود داده ها باید در یک سیستم تصویر مناسب مثلا سیستم تصویر UTM پروجکت شده باشند.
همچنین نیاز است که محدوده عملیات به دقت مشخص باشد. در این تجربه، ما از محدوده ی عارضه ی چندضلعی محل مورد مطالعه برای استخراج اتوماتیک محدوده ی عملیات استفاده می کنیم.
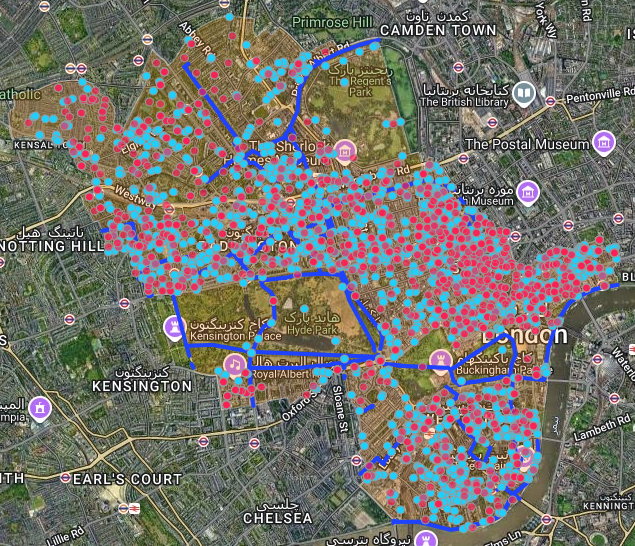
محدوده و نقشه ی داده ها
همانطور که پیشتر گفته شد در این تجربه از ابزارهای موجود در سامانه Geopack Geoportal استفاده می شود. برای این منظور یک گردش کار طراحی شده است که در شکل بخش مربوط به ورودی های روال اجرایی آنرا مشاهده می کنید.
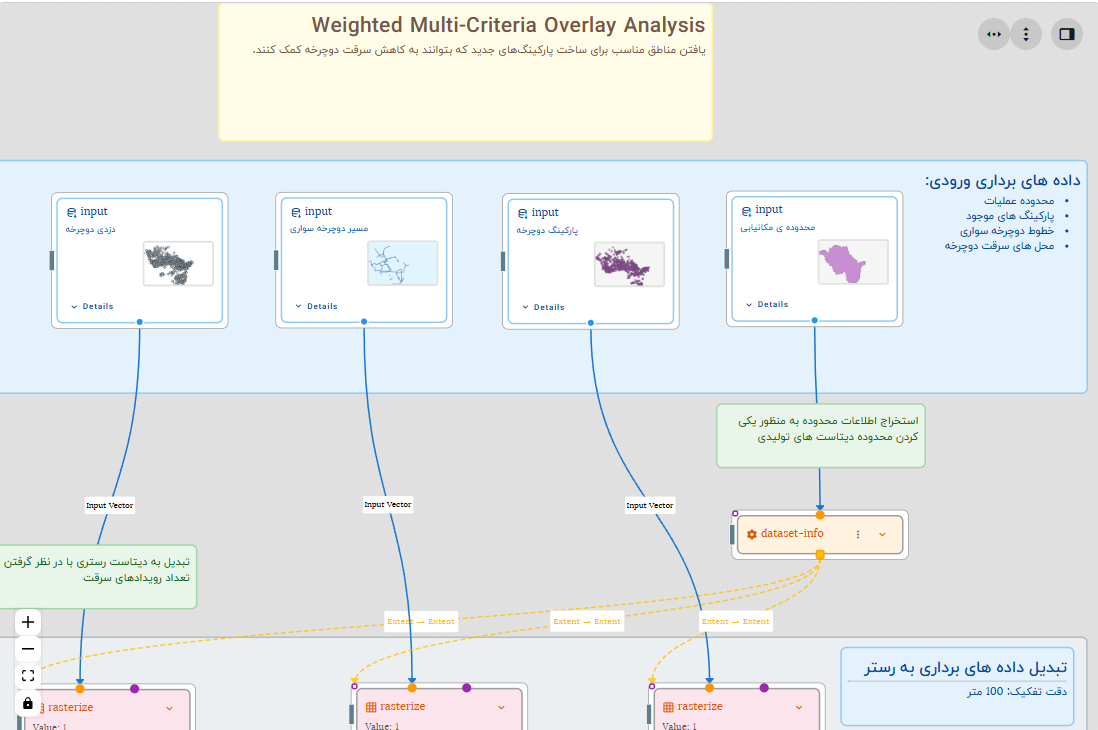
گردش کار- تعیین دیتاست های ورودی
تبدیل دادههای برداری به رستری
اولین قدم برای انجام تلفیق، تبدیل داده های برداری به رستر است. برای این کار از تابع rasterize استفاده می کنیم. این تابع داده ی ورودی را تبدیل به یک رستر می کند که مقادیر آن موقعیت عوارض را نمایش می دهد. این تابع می تواند مقدار یک خصوصیت عارضه را به عنوان مقدار سلول های رستر قرار دهد یا اینکه به کل محدوده ی عارضه یک مقدار ثابت نسبت دهد. در مورد ورودی های ما چون فقط موقعیت عارضه مهم است، از مقدار ثابت 1 برای تعیین مقادیر رستر استفاده می کنیم. در مورد ورودی نقاط محل سرقت، چون تکرار سرقت نشانه ناامن بودن بیشتر محل است می توانیم با فعال کردن خصوصیت "Add Values" در تابع rasterize به ازای هر تکرار مقدار ثابت 1 را به مقدار رستر اضافه کنیم تا مقدار رستر تعداد موارد سرقت را نمایش دهد. در مورد قدرت تفکیک یا اندازه سلول های رستر در این تجربه مقدار 100 در 100 متر برای رسترهای خروجی در نظر گرفته شده است. همچنین توسط تابع dataset-info محدوده ی عملیات استخراج و به عنوان محدوده رسترهای خروجی استفاده می شود تا همه رسترها دقیقا هم اندازه و روی هم قرار بگیرند.
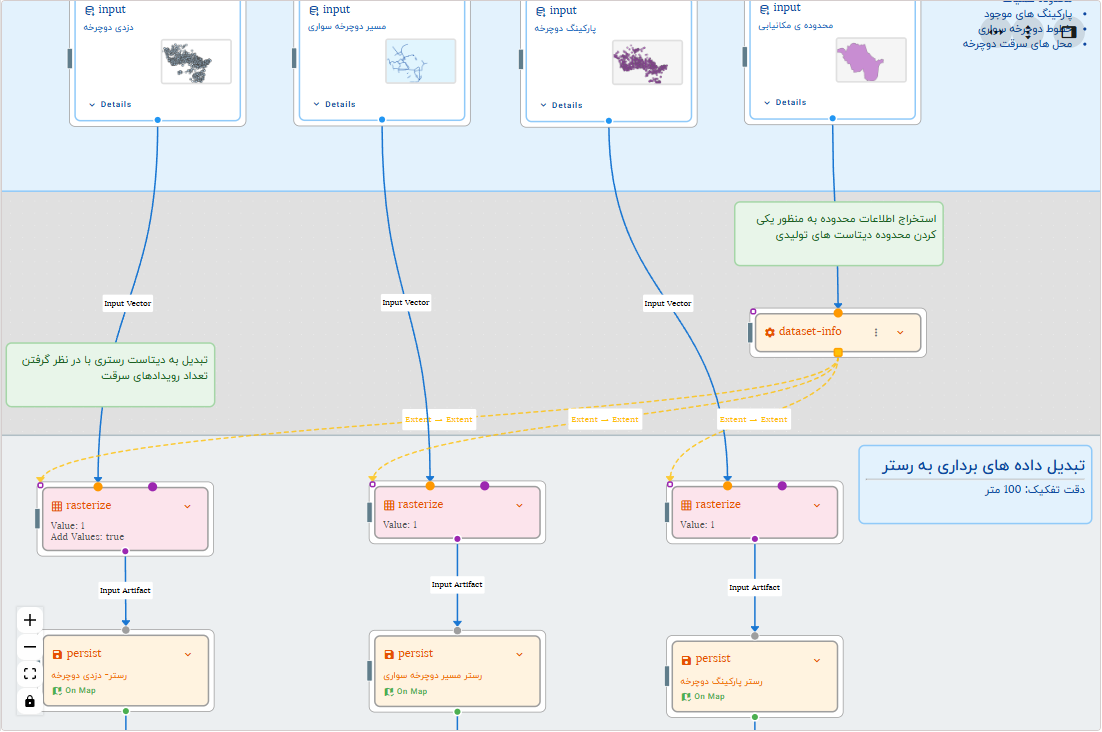
گردش کار- تعیین دیتاست ها به تصویر رستری
توجه: در نمودار روال گردش کار الزامی به ذخیره خروجی رستر به عنوان یک دیتاست مجزا توسط تابع persist نیست و ما این کار را فقط برای نمایش داده های میانی انجام داده ایم. خروجی هر تابع می تواند به صورت مستقیم به عنوان ورودی تابع بعدی استفاده شود.
ایجاد رسترهای مجاورت
برای اینکه بتوان میزان دوری یا نزدیکی به محل های خاص را در محاسبات دخالت داد لازم است که از تابع نزدیکی یا مجاورت (Proximity) استفاده کنیم. این تابع یک رستر جدید می سازد که مقادیر سلولهای آن بیانگر فاصله تا نزدیکترین سلول های با مقادیر خاص رسترهای ورودی است.
در مورد مسیر دوچرخه سواری این رستر مجاورت کمک می کند تا به مناطق نزدیکتر به مسیرهای دوچرخه سواری موجود اولویت بیشتری بدهیم.
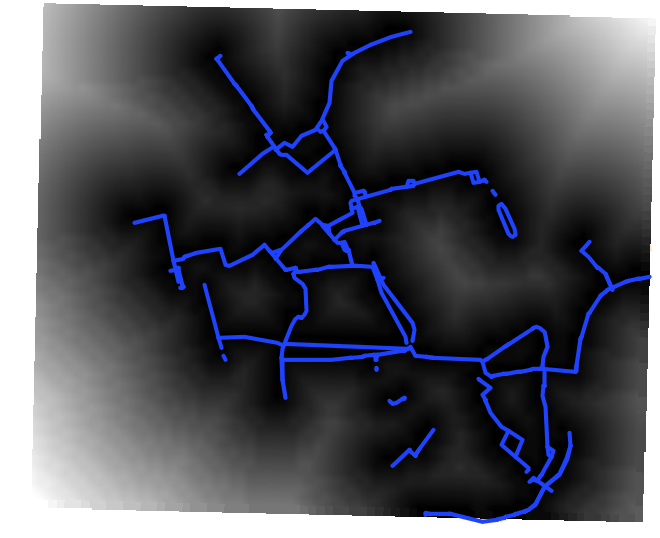
رستر مجاورت نسبت به مسیر دوچرخه سواری
برای اینکه بتوانیم تاثیر دوری از پارکینگ های موجود را نیز اعمال کنیم نیاز است تا اول رستر نزدیکی به پارکینگ ها را ایجاد کنیم تا در مرحله وزن دهی به مناطق دورتر وزن بیشتری بدهیم.
برای اعمال نزدیکی به محل های رویداد سرقت هم می توانیم یک رستر نزدیکی به نقاط سرقت ایجاد کنیم ولی در بعضی از نقاط تکرار سرقت موجب می شود که اهمیت بیشتری داشته باشند و نیاز است که این اهمیت در رستر نزدیکی نیز اعمال شود. ساختن چنین رستری نیاز به روال پیچیده تری (مثلا ایجاد یک رستر هیت-مپ یا یک رستر براساس درونیابی به روش وزندهی معکوس فاصله) دارد. به جای این کار چون ابعاد سلول خروجی رستر نقاط دزدی نسبتا بزرگ هست از ایجاد چنین رستری برای نقاط سرقت انصراف می دهیم و خود آن را برای وزندهی های بعدی در نظر می گیریم.
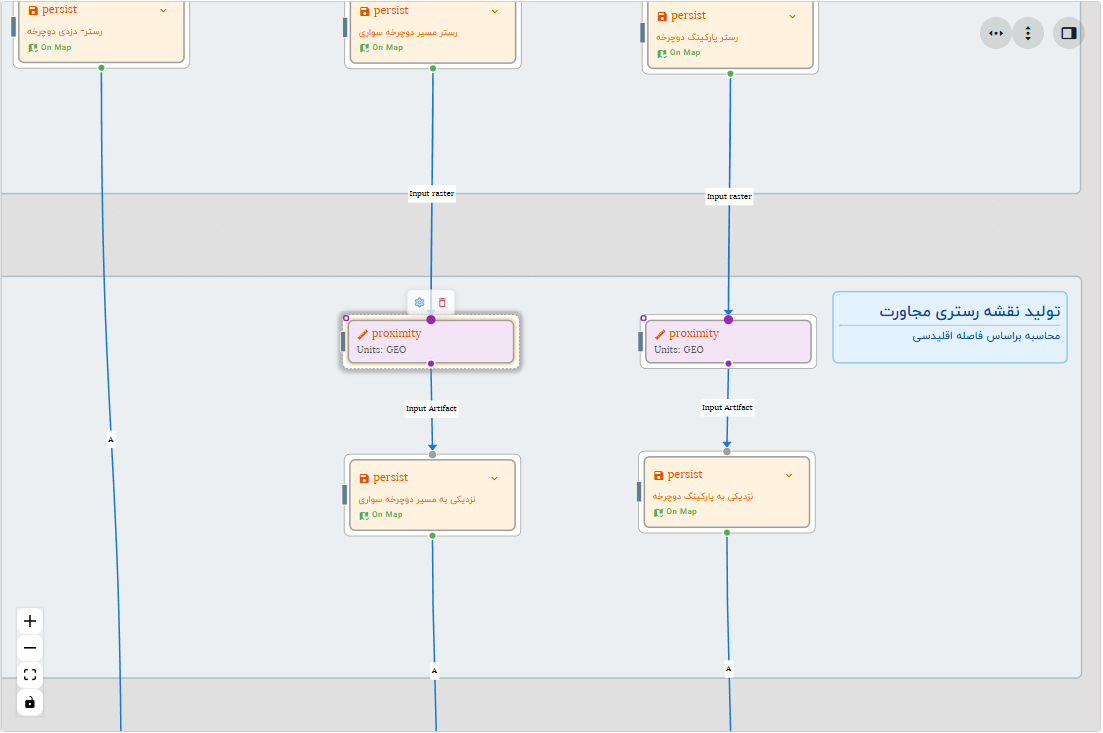
گردش کار- ایجاد رسترهای مجاورت
وزن دهی، طبقه بندی و نرمالسازی
در این مرحله رسترهای موجود را وزن دهی و همزمان طبقه بندی و مقادیر آنها را در بازه ی 0 تا 100 نرمال می کنیم.
برای این کار از تابع raster-calculator استفاده می کنیم. در این تجربه اعداد وزنها و کلاس ها صرفا به منظور آموزش استفاده شده اند، در یک مکانیابی واقعی باید از نظر کارشناسان برای تعیین وزن ها و تعداد کلاس های مورد نیاز برای هر رستر بهره گرفت.
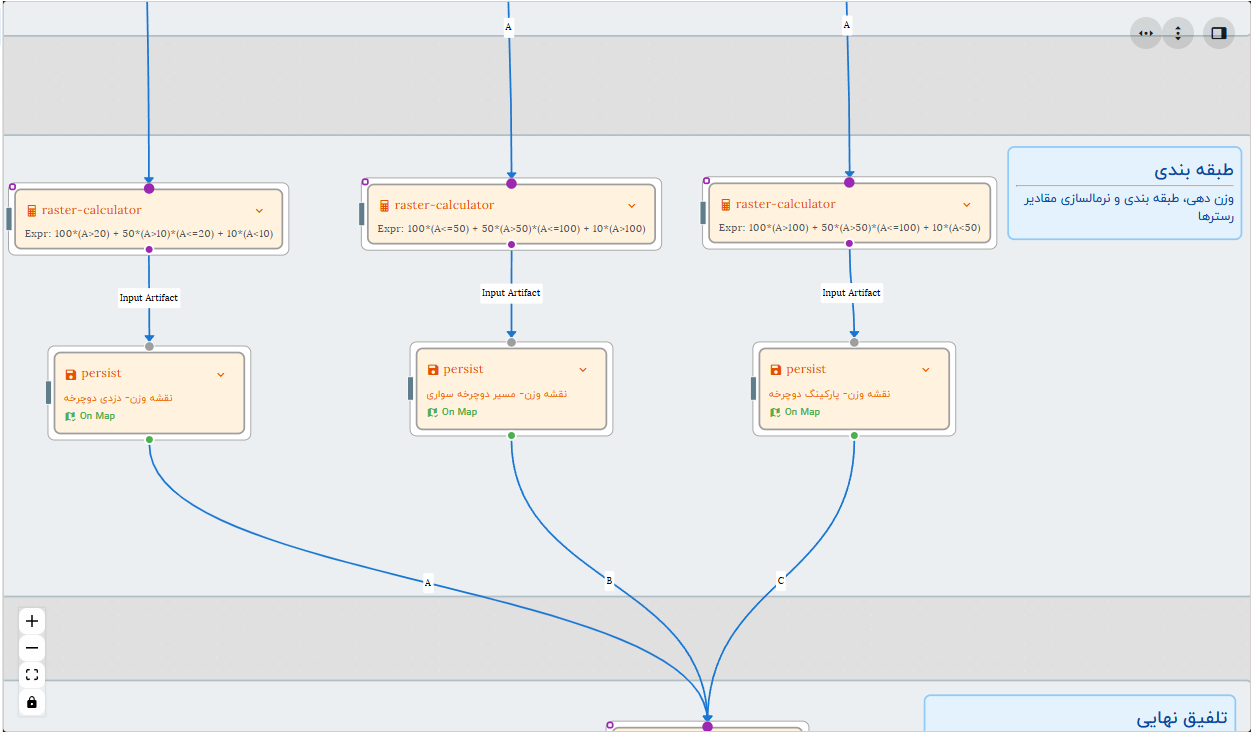
گردش کار- وزن دهی، طبقه بندی و نرمالسازی
- نقشه وزن مسیر دوچرخه سواری: برای تعیین اولویت نزدیکی به مسیر دوچرخه سواری از فرمول زیر به عنوان عملگر محاسباتی استفاده می کنیم:
100*(A<=50) + 50*(A>50)*(A<=100) + 10*(A>100)
این فرمول به این معنی است که مقادیر موجود در رستر مجاورت را به سه دسته تقسیم کن. به سلولهایی که در فاصلهی کمتر یا مساوی 50 متر از مسیر دوچرخه سواری قرار دارند اولویت اول و مقدار 100 بده و به فواصل بین 50 تا 100 متر مقدار 50 و فواصل بیشتر از 100 متر را مقدار 10 در نظر بگیر.
نقشه وزن مسیر دوچرخه سواری
- نقشه وزن پارکینگ های موجود: به منظور تعیین اولویت برای نقاط دورتر از محل پارکینگ های موجود عبارت محاسباتی را به شکل زیر وارد می کنیم:
100*(A>100) + 50*(A>50)*(A<=100) + 10*(A<50)
در این حالت به سلول هایی که در فاصله بیشتر از 100 متر از محل پارکینگ های موجود قرار دارند مقدار 100 و به سلول های بین 50 تا 100 متر مقدار 50 و نزدیکتر از 50 متر را مقدار حداقلی 10 اختصاص می دهیم.

نقشه وزن پارکینگ های موجود
- نقشه وزن دزدی دوچرخه: برای اختصاص اولویت به نقاطی که سابقه سرقت بیشتری در آنها وجود دارد می توانیم به شکل زیر لایه رستری نقاط دزدی را که مقدار سلول آن بیانگر تعداد سرقت هاست دسته بندی و مقادیر را در بازه 0 تا 100 نرمالسازی کنیم.
100*(A>20) + 50*(A>10)*(A<=20) + 10*(A<10)
در اینجا به سلول هایی که بیشتر از 20 مورد سرقت را نشان می دهند وزن 100، بین 10 تا 20 وزن 50 و کمتر از 10 مورد وزن 10 داده شده است.
هماهنطور که قبلا گفته شد می توان یک رستر پیوسته براساس ترکیب فاصله و تعداد سرقت نیز ایجاد کرد و دسته بندی را بر روی آن انجام داد تا وزن ها فقط به سلول های محل اصلی سرقت منتسب نشوند.
نقشه وزن دزدی دوچرخه
همپوشانی وزندار رسترها (Weighted Overlay)
پس از آماده سازی و نرمالسازی رسترهای مورد نیاز نوبت به همپوشانی آن ها می رسد. برای این منظور نیاز است که وزن هر رستر را برای تولید خروجی نهایی معرفی کنیم.
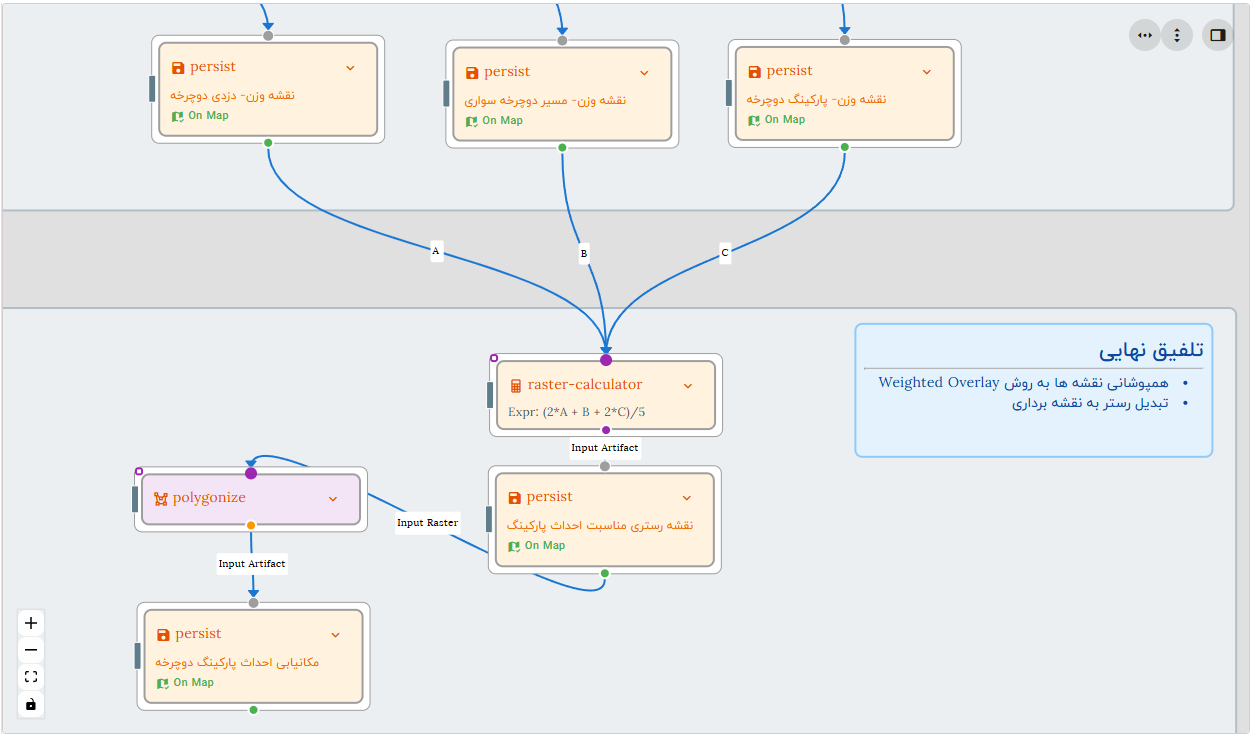
گردش کار- همپوشانی نهایی و تولید رستر و پلیگونهای مکانهای پیشنهادی
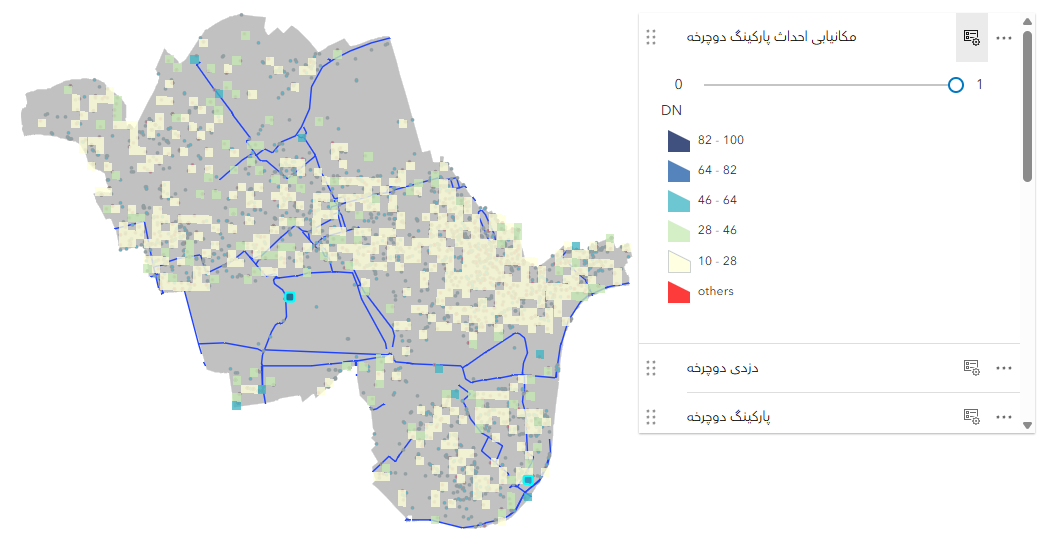
پس از مشخص کردن وزنها (به هر روش مثلا AHP یا به صورت دستی براساس نظر و تجربه کارشناسان) می توانیم توسط عبارت محاسباتی شبیه زیر، رستر نهایی را تولید کنیم.
(2*A + B + 2*C)/5
در این مثال فرض شده است که A رستر نقشه ی وزن دزدی دوچرخه است که با ضریب 2 اعمال می شود. B رستر نقشه وزن مسیر دوچرخه سواری است که برای آن ضریب 1 در نظر گرفته شده است و C رستر نقشه ی پارکینگ های موجود است که با ضریب 2 در محاسبه شرکت می کند.
در رستر تولیدی سلول های با مقادیر بیشتر نشان دهنده مناطق با اولویت بیشتر برای ایجاد پارکینگ های جدید است.
نتیجه نهایی